How did I build Alippo's search from scratch? - Part 2
In part 1, we provided a high-level overview of how we developed the search system at Alippo, focusing on ingestion processes and data synchronisation between the main database and the Elasticsearch cluster. If you haven’t seen it yet, please check it out here.
In this article, we’ll delve into the design choices we made to achieve our desired system. We analyzed the search systems of platforms like Udemy, Swiggy, and Zomato to guide our development.
Understanding User Flow
Before building the product, our primary focus was to clearly understand the user flow:
- How will we show search suggestions based on the query?
- What action will be taken when a user clicks on one of the suggestions?
With this understanding, we could then develop the APIs and system around these requirements.
Key Features to Build
-
Content Type Suggestions: We needed to show suggestions to users for all content types in our system, such as Category, Course, and Instructors.
-
Unified Search Result Page: We had to determine how to render all types of content responses on a single screen.
Design Insights
While researching, I discovered LinkedIn’s tech blog, which mentioned their creation of a more generic search component to support various search types. This significantly reduced the time required to introduce a new search entity, from around a 21 weeks to 1 weekcheck this. However, this wasn’t an issue for us, as we already had our Design Language System (DLS) to render BE-controlled UI on the mobile app. Adding a new search entity was as simple as selecting the component type to render and returning it. I can discuss the development of our DLS in another blog.
Handling Multiple Content Types
During our brainstorming sessions, we debated whether to store different content type data in separate indices. This would mean firing queries to all indices and compiling the final result based on each response.
Alternatively, we considered maintaining a global index that included all content types along with their titles, descriptions, and other fields for full-text search. This allowed us to render all content types in the search suggestion. For the final search result, we would render one searchable entity, which was courses in our case (see the diagram for better understanding).
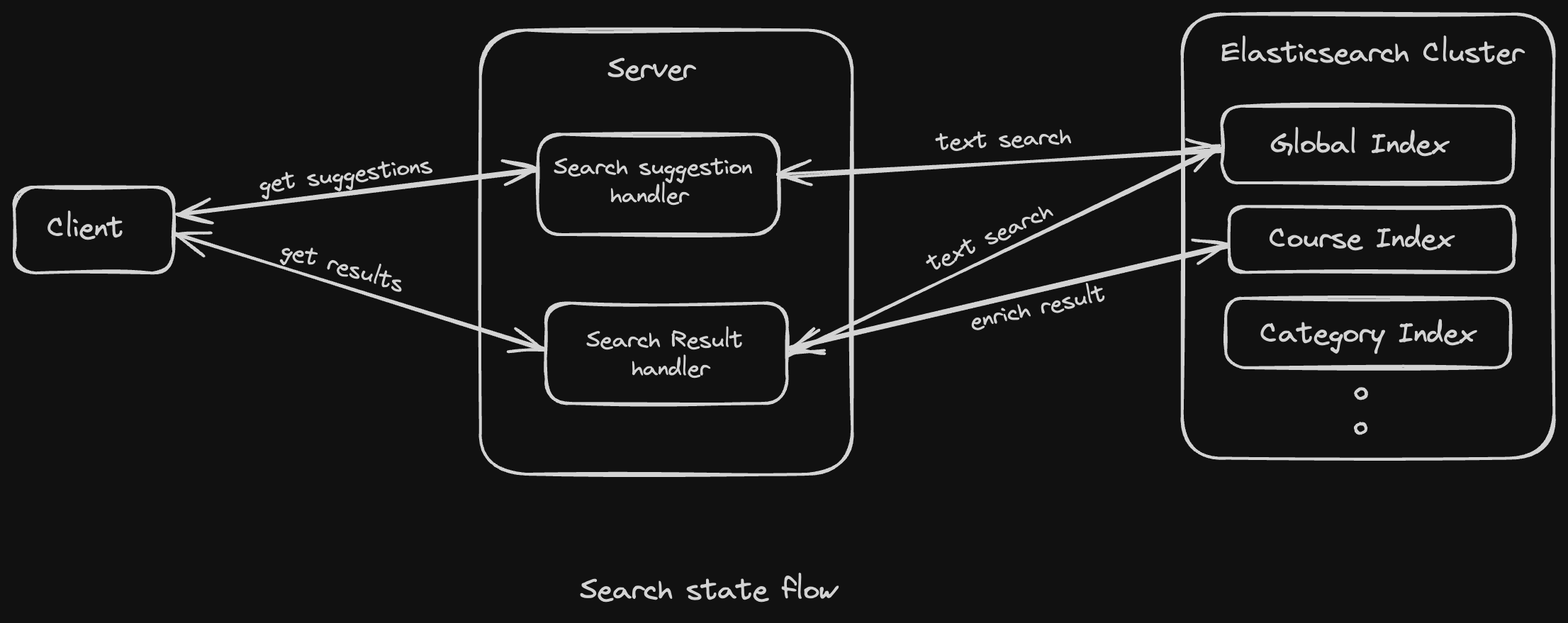
The above approach reduced our need to query multiple indices simultaneously and supported multiple content types using a single index for suggestions. For the search result, we could pass the final entity type (like course, category, instructor) to the server, which would then enrich the result data based on the index of that content type.
Maintaining Consistency
This approach added the overhead of maintaining consistency between different indices. If something changed in the course index, we also needed to update the global index. To achieve this, we modified our ingester server (discussed in the previous blog) to allow each content type entity to declare its dependent entities. Thus, when changes were made in the course, it would trigger an update event for the global index, ensuring consistency across indices.
No system design is perfect, everything comes with pros and cons. The choices we made served us well for our usecase, would love to get your views on this in comments.
I hope you enjoyed the short series on our Search System. I learned a lot during its development and am excited to share these insights with you.
Published on May 20, 2024